篇首语:本文由编程笔记#小编为大家整理,主要介绍了还在调API写所谓的AI“女友”,唠了唠了,教你基于python咱们“new”一个(深度学习)相关的知识,希望对你有一定的参考价值。
诶,标题有点欠揍是吧。好吧承认有点标题党了,拖更大王要更新了。什么你是从这篇博文:快速构建一个简单的对话+问答AI (上)过来的。好吧被你发现了,我是把中间那一段拆开来了。好吧,之所以这样做其实还是因为那篇文章是在是太长了,没写清楚,同时每一个模块都是独立的,因此的话咱们专门拆开来再说下是咋干的。咱们这是一篇独立的博文,那么为啥要独立捏,因为我知道你可能并不需要一个比较完整的内容,如果你关注的是如何实现一个对话AI的话,那么来这里就对了。我们将单独从数据集开始再讲起。并且将真正完整的代码直接在咱们的博文当中贴出了。(因为第三个模块还在做,暂时没有上传仓库)还是那句话,如果关注的是一个闲聊对话AI是如何实现的话,come here!!!
当然标题有点夸张,但是你要做一个所谓的对话AI女友是完全可以的,至少我们可以自己做服务了,当然调用服务,例如图灵机器人啥的还是不错的,少掉不少头发呢。
首先是目录结构,你需要按照框起来的地方进行创建文件。

这里的话我就不去上次仓库了,自己看着这个目录创建,或者等我完整的项目上传到GitHub后自己提取对应的文件。
那么同时的话,对应的资源比如语料资源在这:
链接:https://pan.baidu.com/s/1Bb0sWcITQLrkibDqIT8Qvg
提取码:6666
里面包含了语料和停用词,分词之类的
他们的格式是这样的:
打开之后的话,格式大概是这样的:

词库的格式也是类似的。
这个闲聊也简单,是这样的:

E 是开始标志
M 对话
这个到时候怎么用,咱们在后面再说。
ok,我们这边都创建好了资源都准备好了。那么现在我们把资源放到对应的位置:
这部分的话我们先前说过,但是呢,这个是独立的博文,因此咱们重复一下。
计算机和我们人类是不一样的,他只能进行基本的数字运算,在咱们先前的图像处理当中,图像的表达依然还是通过数值矩阵的,但是一个句子或者单纯是如何表示的呢。所以为了能够让计算机可以处理到咱们的文本数据,咱们需要对文本做一点点处理。
那么在这里是如何做的呢,其实很简单,既然计算机只能处理数字,对数字进行运算,那么我们只需要把我们的一个句子转化为一种向量就好了。那么这个是如何做的呢?
其实非常简单。
看下面一组图就明白了:
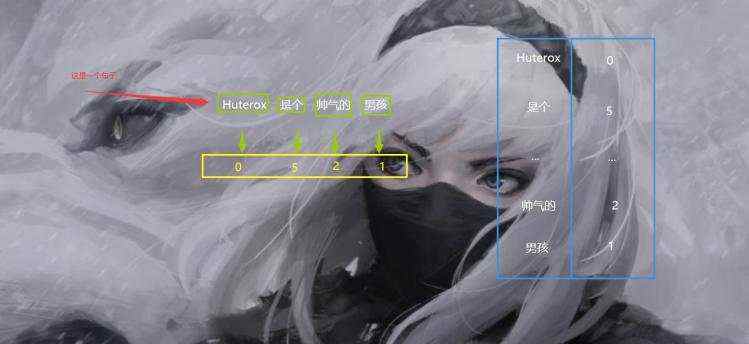
我们通过一个词典其实就可以完成一个向量的映射。
看到了吧,我们这个时候我们只需要对一个句子进行分词,之后将每一个词进行标号,这样一来就可以实现把一个句子转化为一个向量。
此时我们得到了一组序列,但是这个序列的表达能力是在是太弱了,只能表示出一个标号,不能表示出其他的特点。或者说,只有一个数字表示一个词语实在是太单调了,1个词语也应该由一个序列组成。那么这个时候one-hot编码就出来了。他是这样做的:

首先一个词,一个字,我们叫做token,那么编码的很简单。其实就是这样:

但是这样是有问题的,那就是说,我们虽然实现了一个词到向量的表示。但是这个表示方法显然是太大了,假设有10000个词语,那么按照这种方式进行标号的话,那么1个词就是10000个维度。这样显然是不行的。所以这块需要优化一下。
这个原来解释起来稍微复杂一点。你只需要需要知道他们的本质其实就是这样的:
词 ——> 向量空间1 ——> 向量空间2
现在向量空间1不合适,所以我们要想办法能不能往空间2进行靠拢。
于是乎这里大概就有了两个方案:
1)尝试将词向量映射到一个更低维的空间;
2)同时保持词向量在该低维空间中具备语义相似性,如此,越相关的词,它们的向量在这个低维空间里就能靠得越近。
对于第一个,咱们可以参考原来咱们做协同过滤推荐dome的时候,使用SVD矩阵分解来做。(关于这篇博文的话也是有优化的,优化方案将在本篇博文中查看到,先插个眼)
那么缺点的话也很明显嘛,用咱们的这个方案:
1)亲和矩阵的维度可能经常变,因为总有新的单词加进来,每加进来一次就要重新做SVD分解,因此这个方法不太通用;
2)亲和矩阵可能很稀疏,因为很多单词并不会成对出现。
ok,回到咱们的这个(这部分可以选择跳过,知道这个玩意最后得到的是啥就好了),这个该怎么做,首先的话,实现这个东西,大概是有两种方案去做:Continuous Bag Of Words (CBOW)方法和n-gram方法。第一个方案的话,这个比较复杂,咱们这里就不介绍了。
咱们来说说第二个方案。
首先咱们来说说啥是N-gram,首先原理的话也是比较复杂的,具体参考这个:https://blog.csdn.net/songbinxu/article/details/80209197
那么我们这边就是简单说一下这个在咱们这边N-gram实际是咋用的。
[cuted[i:i+2]for i in range(len(cuted))]
其实就是这个,用代码表示,cuted是一个分好词的句子。i+2表示跨越几个。
这样做的好处是,通过N-gram可以考虑到词语之间的一个关系,如果我们使用这个方案来实现一个词向量的话,那么我们必然是可以能够实现:“同时保持词向量在该低维空间中具备语义相似性,如此,越相关的词,它们的向量在这个低维空间里就能靠得越近。”的。因为确实考虑到了之间的一个关系,那么现在我们已经知道了大概N-garm是怎么样的了,其实就是一种方式,将一个句子相近的词语进行连接,或者说是对句子进行一个切割,上面那个只是一种方式只有,这个我们在后面还会有说明,总之它是非常好用的一种方式。
ok,知道了这个我们再来介绍几个名词:
1.跳词模型
跳词模型,它是通过文本中某个单词来推测前后几个单词。例如,根据‘rabbit’来推断前后的单词可能为‘a’,‘is’,‘eating’,‘carrot’。在训练模型时我们在文本中选取若干连续的固定长度的单词序列,把前后的一些单词作为输出,中间的某个位置的单词作为输入。
2.连续词袋模型
连续词袋模型与跳词模型恰好相反,它是根据文本序列中周围单词来预测中心词。在训练模型时,把序列中周围单词作为输入,中心词作为输出。
这个的话其实和我们的这个关系不大,因为N-gram其实是句子–>词 的一种方式,但是对我训练的时候的输入还是有帮助的,因为这样输入的话,我们是可以得到词在句子当中的一种关联关系的。
而embedding是词到one-hot然后one-hot到低纬向量的变化过程。
ok,扯了那么多,那么接下来看看我们如何实现这个东西。
我们需要一个词向量,同时我们有很多词语,因此我们将得到一个矩阵,这个矩阵叫做embedding矩阵。
我们首先随机初始化embeddings矩阵,构建一个简单的网络。初始化weights和biases,计算隐藏层的输出。然后计算输出和target结果的交叉熵,之后使用优化器完成一次反向传递,更新可训练的参数,包括embeddings变量。并且我们将词之间的相似度可以看作概率。
ok,我们直接看到代码,那么咱们也是有两个版本的。简单版,复杂版。
简单版本的话,在pytorch当中有实现:
embed=nn.Embedding(word_num,embedding_dim)
那么我们显然是不满足这个的,那么我们还有复杂版本。就是自己动手,丰衣足食!
首先我们定义这个:
class embedding(nn.Module):
def __init__(self,in_dim,embed_dim):
super().__init__()
self.embed=nn.Sequential(nn.Linear(in_dim,200),
nn.ReLU(),
nn.Linear(200,embed_dim),
nn.Sigmoid())
def forward(self,input):
b,c,_=input.shape
output=[]
for i in range(c):
out=self.embed(input[:,i])
output.append(out.detach().numpy())
return torch.tensor(np.array(output),dtype=torch.float32).permute(1,0,2)
很简单的一个结构。
那么我们输入是上面,首先其实是我们one-hot编码的一个矩阵。
我们其实流程就是这样的:词—>one-hot—>embedding/svd
ok,那么我们的N-gram如何表示呢,其实这个更多的还是在于对句子的分解上,输入的句子的词向量如何表示的。
如何训练的话,首先还是要在one-hot处理的时候再加一个处理,这个过程可能比较绕。就是说我们按照上面提到的词袋模型进行构造我们的数据,我们举个例子吧。
现在有这样的一个文本,分词之后,词的个数是content_size。有num_word个词。
import torch
import re
import numpy as np
txt=[] #文本数据
with open('peter_rabbit.txt',encoding='utf-8') as f:
for line in f.readlines():
l=line.strip()
spilted_sentence=re.split(" |;|-|,|!|\\'",l)
for w in spilted_sentence:
if w !='':
txt.append(w.lower())
vol=list(set(txt)) #单词表
n=len(vol) #单词表单词数
vol_dict=dict(zip(vol,np.arange(n))) #单词索引
'''
这里使用词袋模型
每次从文本中选取序列长度为9,输入单词数为,8,输出单词数为1,
中心词位于序列中间位置。并且采用pytorch中的emdedding和自己设计embedding两种方法
词嵌入维度为100。
'''
data=[]
label=[]
for i in range(content_size):
in_words=txt[i:i+4]
in_words.extend(txt[i+6:i+10])
out_word=txt[i+5]
in_one_hot=np.zeros((8,n))
out_one_hot=np.zeros((1,n))
out_one_hot[0,vol_dict[out_word]]=1
for j in range(8):
in_one_hot[j,vol_dict[in_words[j]]]=1
data.append(in_one_hot)
label.append(out_one_hot)
class dataset:
def __init__(self):
self.n=ci=config.content_size
def __len__(self):
return self.n
def __getitem__(self, item):
traindata=torch.tensor(np.array(data),dtype=torch.float32)
trainlabel=torch.tensor(np.array(label),dtype=torch.float32)
return traindata[item],trainlabel[item]
我们只是在投喂数据的时候按照词袋模型进行投喂,或者连续模型也可以。
当然我们这里所说的都只是说预训练出一个模型出来,实际上,我们直接使用这个结构,然后进行正常的训练完成我们的一个模型也是可以的。她是很灵活的,不是固定的!
那么继续预训练的话就是按照词袋模型来就好了(看不懂没关系,跳过就好了)
import torch
from torch import nn
from torch.utils.data import DataLoader
from dataset import dataset
import numpy as np
class model(nn.Module):
def __init__(self):
super().__init__()
self.embed=embedding(num_word,100)
self.fc1=nn.Linear(num_word,1000)
self.act1=nn.ReLU()
self.fc2=nn.Linear(1000,num_word)
self.act2=nn.Sigmoid()
def forward(self,input):
b,_,_=input.shape
out=self.embed (input).view(b,-1)
out=self.fc1 (out)
out=self.act1(out)
out=self.fc2(out)
out=self.act2(out)
out=out.view(b,1,-1)
return out
if __name__=='__main__':
pre_model=model()
optim=torch.optim.Adam(params=pre_model.parameters())
Loss=nn.MSELoss()
traindata=DataLoader(dataset(),batch_size=5,shuffle=True)
for i in range(100):
print('the epoch'.format(i))
for d in traindata:
p=model(d[0])
loss=Loss(p,d[1])
optim.zero_grad()
loss.backward()
optim.step()
这样一来就可以初步完成预训练,你只需要加载好embeding部分的权重就好了,这个只是加快收敛的一种方式。
最终,词嵌入的话,得到的矩阵是将one-hot变化为了这样的矩阵

ok,词的表达已经🆗了,那么接下来我们在简单介绍一下RNN。
(当然对于这一部分,实际上的话其实还有别的方法,但是咱们这边只是用到这些东西,所以只是介绍这个)
这个RNN的话,咋说呢,其实挺简单的,但是有几个点可能是比较容易误导人的,搞清楚这个结构的话,对于我们后面对于LSTM,GRU这种网络的架构可能会更好了解,其实包括LSTM,GRU的话其实本质上还是挺简单的。当然能够直接提出这个东西的人是非常厉害的,不过不管怎么说他们都是属于循环神经网络的一个大家族的,只是在数据处理上面多了一点点东西。那么理解了RNN之后的话,对于我后面理解LSTM,GRU里面它的一个数据的变幻,传递,原理。因为后面的话,我们还是要手写实现这个GRU的(LSTM也是一样的,但是GRU少了点参数,消耗的计算资源少一点点)。所以对于这一部分还是有必要好好唠一唠的。
首先我们来看到基本的神经网络:
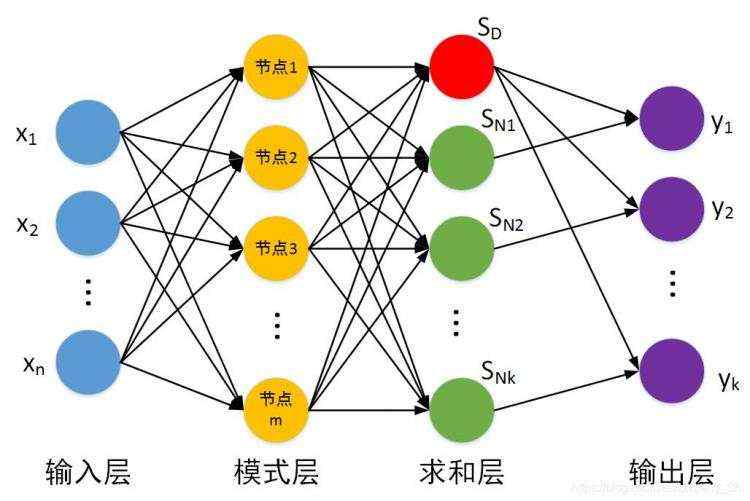
这是一个简单的前馈神经网络,也是我们最常见的神经网络。
接下来是我们的RNN神经网络,在大多数情况下,我们经常会提到这几个名词:时间步,最后一层输出等等。
那么在这里的话,我们需要理解展开的其实只有一个东西,那就是对应时间步的理解,什么是上一层网络的输出,他们之间的参数是如何传递的。
那么在此之前,我们先来看看RNN的网络结构大概是什么样子的。
大多数情况下,你搜索到的图片可能是这样的:
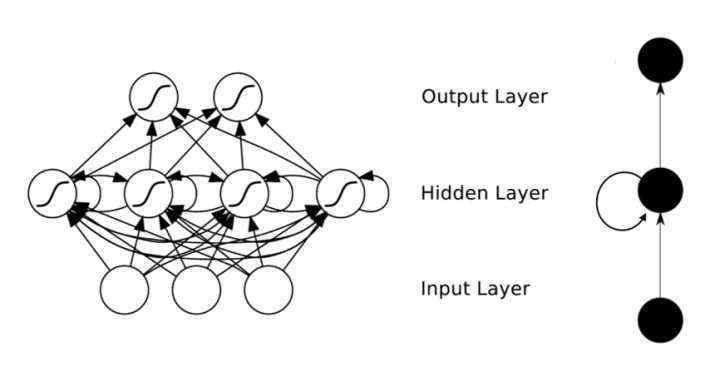
首先承认这张图非常的简洁,以至于你可能一开始没有反应过来,什么体现循环,体现时间步的地方在哪。其实这里的话,这种图其实只是一个缩略平面图。
但是实际上,如果需要用画图来表示的话,RNN其实是立体的一个样子。大概长这个样子:
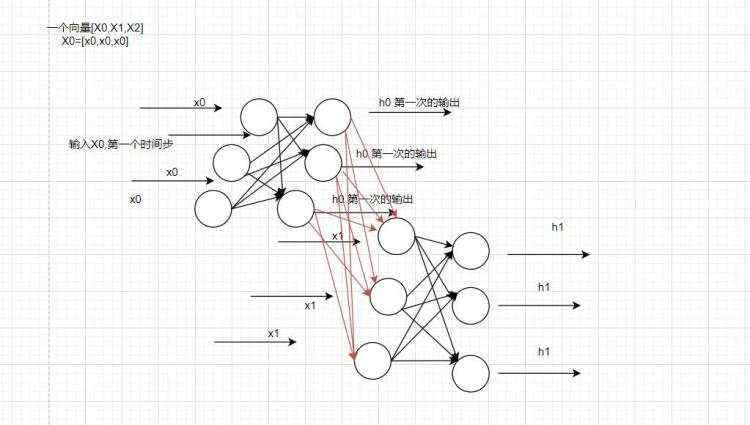
可能有点抽象,但是它的意思其实就是这样的,这个其实是RNN真正的样子,之后通过对不同的时间步的输出进行不同的处理,最终我们还可以将RNN进行分类。
OK,这个就是我们在RNN里面需要注意的点,它的真实结构是这样的,是一个三维度的结构。同样的接下来要提到的LSTM,GRU都是。
OK,接下来还没完,我们现在需要不目光放长远一点,首先是在RNN里面对于层的概念,我们接下来会说什么什么层,搭建几层的一个LSTM,GRU之类的,或者说几层的RNN,这个层其实是指,一个时间步上有几个立体的层,而不是说先前平面的那种网络,说几层几层。因为实际上,咱们这里图画的就一层全连接(输入层不算),但是在时间步上,它是N层,你有几个X就有几个层。
我们拿一个句子为例,假设一句话有5个单词,或者说处理之后有5个词语。那么RNN就是把每一个词的词向量作为输入,按照顺序,按照上面图的顺序进行输入。此时需要做的就是循环5次。
那么之后的话,咱们再来说说LSTM和GRU,他们呢叫做长短期记忆网络,其实就是最low的RNN的一个升级版,对信息进一步处理。我们对于模型的调优,优化说白了,除了性能的优化,就是对信息的最大利用(增加信息,或者对重点信息进行提取)。所以基本上为什么大模型的效果很好,其实不考虑对信息的利用率,单单是对信息的使用就已经达到了超大的规模,这效果肯定是比小模型好一点的。
那么这里的话,我们就简单过一下这个结构图吧。
首先是LSTM,其实的话他这里主要是引入了一个东西,叫做记忆。
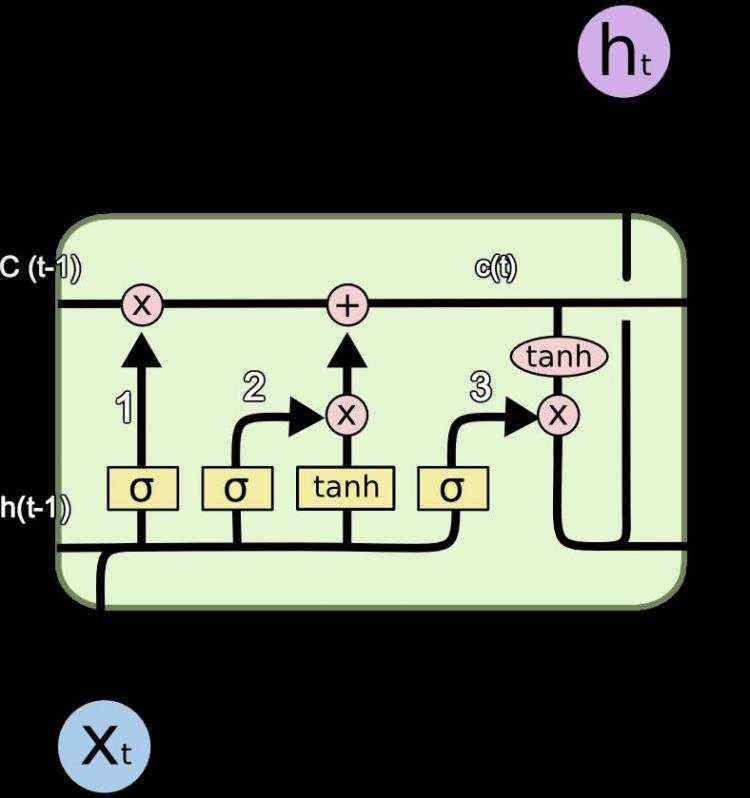
c就是记忆,因为刚刚的RNN,的话其实更像是一个一阶的马尔科夫,那么导入这个的话,就相当于日记,你不仅仅知道了昨天做了什么,还知道了前天做了什么,这样的话对于信息的利用坑定是上去了的。那么这个是它的一个单元。
宏观上还是这样的:
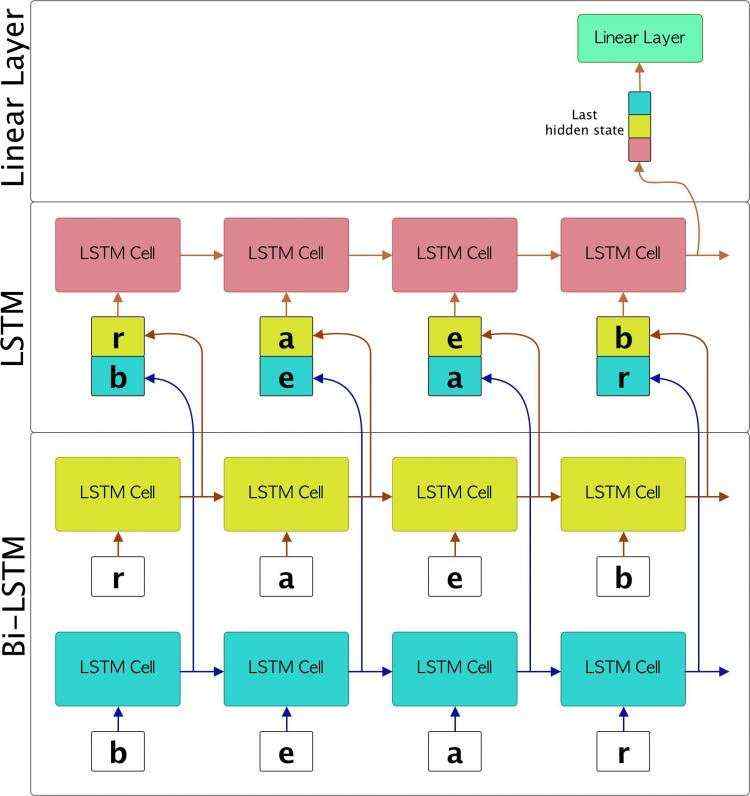
同理GRU也是一样的

但是这里的话少了一个c 其实还是说把Ht和c合在了一起,他们效果是差不多的,各有各的好处,你用LSTM还能多得到一个日记本,用GRU的话其实相当于,你把日记写在了脑子里面。好处是省钱,坏处是有时候要你女朋友可能需要检查日记(虽然我知道你有95%以上的概率是没有的,一般设置0.05 作为阈值,低于这个概率,基本上我们认为G了)
ok,这些我们都说完了
nice到这里了,这部分的话,我们还需要知道一些东西。我们现在知道了图的表达,也知道了RNN大概是啥,啥是时间步之类的。这里重点对应RNN就是那玩意是3维的,包括那个LSTM,GRU其实都是。
那么现在还需要干啥呢,当然是第一部分,我们要把词变成序列呀。
在开始之前,我们还需要给出配置哈,那么我们这里先给出来,在这里:

"""
just configuration for this project to run
"""
import pickle
auto_fix = True
jieba_config =
"word_dict":"./../../data/word/word40W.txt",
"stop_dict":"./../../data/word/stopWordBaiDu.txt",
data_path =
"xiaohuangji": "./../../data/XiaoHuangJi50W.conv",
"QA": "./../../data/QA5W.json"
"""
Encoder and Decoder using same config params in here
"""
chatboot_config =
"target_path_no_by_word":"./../../data/chat/target_no_by_word.txt",
"input_path_no_by_word": "./../../data/chat/input_no_by_word.txt",
"word_corpus_no_by_word_input":"./../../data/chat/word_corpus_input_no_by_word.pkl",
"word_corpus_no_by_word_target":"./../../data/chat/word_corpus_target_no_by_word.pkl",
"target_path_by_word": "./../../data/chat/target_by_word.txt",
"input_path_by_word": "./../../data/chat/input_by_word.txt",
"word_corpus_by_word_input": "./../../data/chat/word_corpus_input_by_word.pkl",
"word_corpus_by_word_target": "./../../data/chat/word_corpus_target_by_word.pkl",
"seq2seq_model_no_by_word":"./../../data/chat/seq2seq_model_no_by_word.pth",
"optimizer_model_no_by_word":"./../../data/chat/optimizer_model_no_by_word.pth",
"seq2seq_model_by_word": "./../../data/chat/seq2seq_model_by_word.pth",
"optimizer_model_by_word": "./../../data/chat/optimizer_model_by_word.pth",
"batch_size": 128,
"collate_fn_is_by_word": False,
"input_max_len":12,
"target_max_len": 12,
"out_seq_len": 15,
"dropout": 0.3,
"embedding_dim": 300,
"padding_idx": 0,
"sos_idx": 2,
"eos_idx": 3,
"unk_idx": 1,
"num_layers": 2,
"hidden_size": 128,
"bidirectional":True,
"batch_first":True,
# support 0,1,..3(gpu) and cup
"drive":"0",
"num_workers":0,
"teacher_forcing_ratio": 0.1,
# just support "dot","general","concat"
"attention_method":"general",
"use_attention": True,
"beam_width": 3,
"max_norm": 1,
"beam_search": True
def chat_load_(path,by_word,is_target,fixed=True, min_count=5):
from corpus.chatbot_corpus.build_chat_corpus import Chat_corpus, compute_build
after_fix = False
ws = None
try:
ws = pickle.load(open(path, 'rb'))
except:
if (auto_fix):
print("fixing...")
chat_corpus = Chat_corpus()
compute_build(chat_corpus=chat_corpus, fixed=fixed, min_count=min_count,
by_word=by_word, is_target=is_target)
after_fix = True
if (after_fix):
ws = pickle.load(open(path, 'rb'))
return ws
def word_corpus_no_by_word_input_load():
path = chatboot_config.get("word_corpus_no_by_word_input")
return chat_load_(path,is_target=False,by_word=False)
def word_corpus_no_by_word_target_load():
path = chatboot_config.get("word_corpus_no_by_word_target")
return chat_load_(path,is_target=True,by_word=False)
def word_corpus_by_word_input_load():
path = chatboot_config.get("word_corpus_by_word_input")
return chat_load_(path,is_target=False,by_word=True)
def word_corpus_by_word_target_load():
path = chatboot_config.get("word_corpus_by_word_target")
return chat_load_(path,is_target=True,by_word=True)
chatboot_config_load =
"word_corpus_no_by_word_input_load": word_corpus_no_by_word_input_load(),
"word_corpus_no_by_word_target_load": word_corpus_no_by_word_target_load(),
"word_corpus_by_word_input_load": word_corpus_by_word_input_load(),
"word_corpus_by_word_target_load": word_corpus_by_word_target_load(),
这个的话,是我们对话AI需要的配置文件。
ok,我们开始准备数据集了。这里注意咯,如果你想要训练出一个AI女友的话,这部分很关键哟~。首先数据是这个样子的。
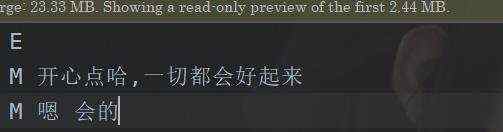
那么我们要做的是啥呢,首先我们这里把第一句话作为我们的输入,也就是说我们假设,第一句话是你要说的话。第二句话是你期望AI输出的话,那么我们把第一句话作为input,第二句作为target。我们期望的是,你输入一个input,AI能够输出类似与target的话来。
那么我们先要做的就是对数据的切分。
这个就是我们切分之后的结果:
我们这里的话还可以实现按照一个一个字来分和按照jieba进行分词的效果。也就是说如果你觉得按照jieba分词的效果不好,你可以试着直接按照字去分词。
欧克,那么我们现在要做的先是实现我们的分词。
这个的话把代码放在这里:

实现是这个:
"""
this model just for cutting words
"""
import jieba
import jieba.posseg as pseg
from tqdm import tqdm, trange
from config.config import jieba_config
import string
jieba.load_userdict(jieba_config.get("word_dict"))
jieba = jieba
pseg = pseg
string = string
with open(file=jieba_config.get("stop_dict"),encoding='utf-8') as f:
lines = tqdm(f.readlines(),desc="loading stop word")
StopWords = .fromkeys([line.rstrip() for line in lines ]





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 